Project GenCo
GenCo: A Dual LVLM Generate-Correct Framework for Adaptive Peg-in-Hole Robotics
1Department of Chemistry and Materials Innovation Factory, University of Liverpool, Liverpool, United Kingdom
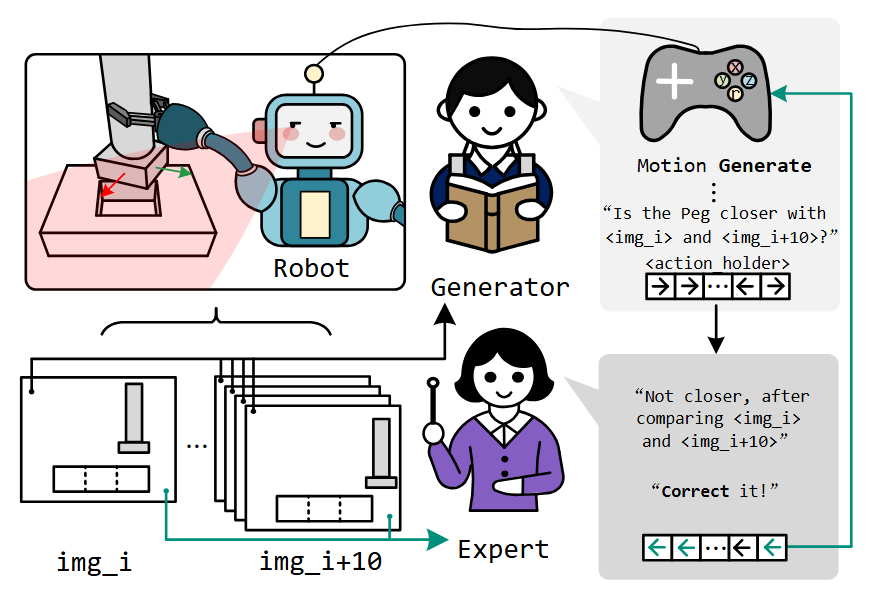
Recent advancements in Large-Vision Language Models (LVLMs) have enhanced their application in robotics, encompassing high-level task planning and low-level action control. Despite their strong performance across various robotic tasks, even for zero-shot scenarios, most LVLM applications remain open-loop, adhering to a plan-and-execute paradigm without mechanisms to assess task completion. To address this limitation, we propose GenCo, a Generate-Correct framework designed to automate a peg-in-hole task using a UR5e robot. This framework integrates an LVLM-based motion generator and motion expert, working collaboratively to refine and correct actions during robotic task execution. Both LVLM agents are fine-tuned using the pre-trained LLaVA, enhancing their adaptability and scaling efficiently to diverse tasks. Our comprehensive experiment demonstrates the adaptiveness of the framework, improving the success rate for the peg-in-hole task by 12.75% compared to a single LVLM open-loop method. Notably, in unseen scenarios, the success rate for the triangular peg increased by 15%, and for the random shaped peg by 17%, underscoring the system's effectiveness in handling novel tasks. Additionally, adaptive testing under varied camera positions demonstrates robust performance, affirming its reliability despite shifts in the visual input. The framework is also designed to be lightweight and efficient, facilitating broader adoption and practical deployment. Access to our code and model is provided here
Graphical Abstract
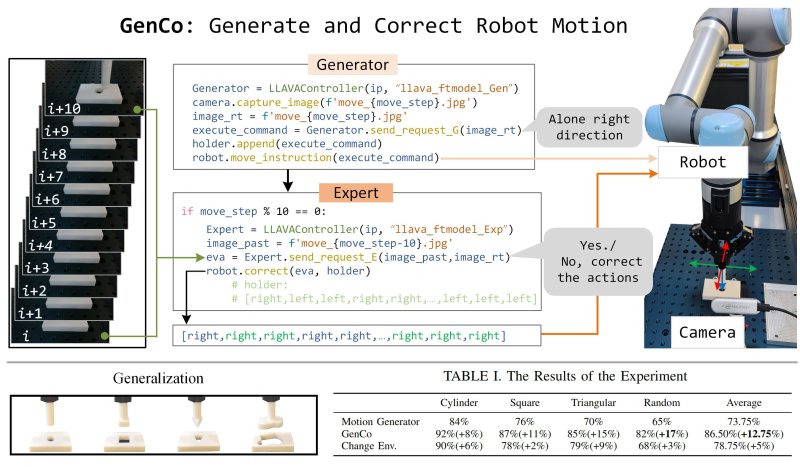
Figure: Proposed Approach